
Gemini Nano in Production: 41% Eligibility, 6x Slower, $0 Cost

We built a feature with Chrome's built-in AI. It's 6x slower than an API call. We're keeping it anyway.
Psst... just show me the stats + charts
TL;DR
We added Google Gemini's Nano (which runs inside of Chrome) to our Email Subject Line Tester and it works, but only for around 41% of our userbase and it's slower than calling an external AI API.
Overall, I'm positive on it and think that it's going to be a game changer for how we use browsers in the future. In particular, if you run a website I think it's probably very important for you to make sure that Gemini Nano likes your site and built another tool to help you check that over at Knowatoa - What's Chrome Saying About You?
The Problem
SendCheckIt is a collection of tools for email marketers, we help you check your email health, if your site is on a blocklist, but our most popular tool is an email subject line tester.
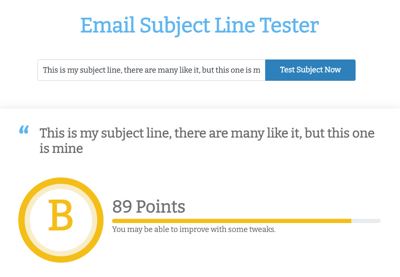
The tester takes a subject line and scores it on a number of different factors, including readability, spam triggers, length, sentiment, and more.
I subscribed to thousands of email newsletters, did a statistical analysis on them to reverse engineer the best subject lines.
We've tested literally millions of subject lines for over 100,000+ email marketers, but to date we've never been able to suggest new subject lines.
Why not to use AI
I know users are popping between ChatGPT and SendCheckIt to get AI generated subject lines and it's easy enough to do the dev work, but there were three major issues holding me back:
- Money.
- Money.
- Money.
The system is popular, free and gets a wild amount of abuse making me very reluctant to add potentially expensive AI features.
The Solution: In Browser AI
Browser functionality has been pretty static for a while, but at one point in the ancient past browsers couldn't display images, render fonts or play embedded videos.
Now Google is pushing things forward by shipping new versions of Chrome (on Desktop and for the English language only) with their Gemini Nano model built in as just part of the browser.
The Implementation
Google ships new versions of Chrome with the capability to run Gemini Nano in browser, but doesn't actually ship the model itself.
Implementation Gotchas
But it is presently possible to do basic capability checks in Javascript and as needed to fallback to a server API if the browser isn't capable of running Gemini Nano.
The Fallback
If the user doesn't have Gemini Nano available, we fall back to Google's Gemma 3N model served via OpenRouter. It's actually slightly more capable than Nano, with a larger effective parameter count (6B vs 1.8B) and longer context window (32K vs 6K). More importantly, it doesn't cost anything.
Server based AI inference is now extremenly cheap if not free.
Finding it was a bit of a surprise as I'm normally much more focused on frontier models and their costs. It's a worthwhile takeaway to try and remember that server-based AI inference is now extremely cheap—if you're not using a frontier state-of-the-art model.
Actual Gemini Nano Eligibility and Performance
Alongside implementing the new feature we instrumented a bunch of stats to try and get our hands around what actual Gemini Nano eligibility and performance looks like as the promise seems...so promising?
Fundamentally, we wanted to answer the following questions:
- What percentage of users could potentially use Gemini Nano today?
- How many already had the model downloaded and ready to go?
- For those who didn't, how long did the model take to download?
- What was the inference performance of Gemini Nano versus the hosted Gemma model?
Stats as of January 2026, based on 12,524 AI generations across 836 users.
User Funnel
Eligibility
Whether or not a Chrome browser is capable of running Gemini Nano goes beyond just version and language, there's specific requirements for CPU, GPU and operating system as well, all of which drives down the true number of users who can use it.
You're better off thinking of the requirements for Nano like that of a AAA video game than a browser feature.
If you were trying to estimate how many of your users are eligible right now, I'd say take your overall Chrome Desktop userbase and chop it in half for a rough estimate.
Model Ready
This number is based upon some early testing we did and not live data as at one point we were kicking off downloads on the homepage in an attempt to make the make the user experience more seamless (the model would be ready by the time users hit the results page).
We also have a very high number of returning users and the mix of this artificially inflated our "live" stats, so we're instead showing the approximate percentage that we observed when we started this and not the actual live number over the past 24 hours.
Model Download Stats
We were able to track download times only for users who stuck around long enough for it to complete on the site, if they left before it was done, we don't know which may artifically make this look better than it is.
Inference Performance
We're consistently getting much better results by calling the Gemma model via an external API, which was a surprise as I figured even slow local inference would be faster than a server round-trip.
Inference Time Distribution
Inference Time Distribution (smaller is better)
Beyond just statistical speed, server based inference has a much smaller performance envelope.
I think the massive times for Gemini Nano in the p90+ range are caused by edge cases where inference is being run on hardware that's just not really capable of handling it.
What Surprised Us
We expected a download prompt to kill conversion
There isn't one. The model download is completely invisible—no confirmation dialog, no progress bar, nothing. It just happens in the background.
The experience is much more seamless to the user than I thought it would be, which is great for adoption, but I have mixed feelings about silently putting a multi-gigabyte download onto users' machines without their explicit knowledge.
We worried about abandoned downloads
What happens if someone starts the 1.5GB download and then closes the tab? Turns out Chrome handles this gracefully: the download continues in the background. If the browser closes entirely, it resumes on next launch (within 30 days).
If the connection drops, it picks up where it left off. The model is managed at the browser level, not the page level.
We expected local inference to be faster than a server round-trip
It's not even close. Gemini Nano's median inference time is around 7.7 seconds. Gemma 3N via the API? About 1.3 seconds. The on-device model is roughly 6x slower than making a network request to a server on another continent.
The "no network latency" benefit is completely overwhelmed by the difference in compute power between a laptop GPU and a datacenter.
"no network latency" is trounced by the compute power difference between a laptop GPU and a datacenter.
We thought we'd need aggressive fallback racing
We considered starting both local and API inference simultaneously, using whichever returns first. Unnecessary—the eligibility check is instant, and users who can't use Nano get routed to the API immediately.
We thought it'd be cheaper
And if you count some pretty ephemeral server costs, technically it is, but even if OpenRouter wasn't offering the Gemma model for free, it would still be a pittance to call something like OpenAI's older models for this task and get equivalent or better performance.
Sidequest Mistake: The Turbo Trap
I ended up invaldating a bunch of our early numbers due to a Rails+Turbo feature I'd forgotten to take into account.
Rails ships with Turbo, which speeds up navigation by prefetching links when you hover over them. Great for performance. Terrible when those links trigger AI inference.

When users get their AI-generated alternative subject lines, each is clickable. The moment users move their mouse across the list, Turbo prefetches each link, triggering five simultaneous AI generation calls.

This broke our data in two ways:
Timing was wildly inflated. Five concurrent Gemini Nano inferences on consumer hardware? The GPU gets hammered. Our initial measurements showed 8x slower than the API. The real number, with the prefetch bug fixed, is closer to 6x.
Usage analytics were undercounted. When you fire off five AI requests simultaneously on a phone or older laptop, things lock up. The browser struggles, requests fail silently, and our tracking calls never complete. We thought only 5-10% of users were getting AI generations. The actual number is closer to 50%.
The fix was simple: adding a data-turbo="false" attribute on the links. But we'd been staring at bad data for weeks, convinced that on-device AI was both slower and less popular than it actually is.
Lesson learned: Nano inference can have user impacting side effects on client side performance.
Why We're Keeping It
Going by the numbers, there is zero reason to use Gemini Nano in production currently.
- It's slow
- It's not available to ~60% of users
- It's not any cheaper than calling an external API (currently, OpenRouter's $40 million in VC dollars might run out at some point they might start charging)
There is zero reason to use Gemini Nano in production currently. We're keeping it anyway.
That being said, I think it's the future. Other browsers are quickly going to incorporate their own AI models, we will see more consistent cross platform APIs, etc.
And if nothing else, I really like the privacy aspects of having and running local models. The more local inference we have happening, the more we'll see OS, browser and app improvements that optimize for both the developer and user experience.